SSD:Single Shot Multibox Detector

Yolo v1 분석에 이어서 오늘은 SSD에 대해 분석하고자 한다. 이 논문에 대한 요약글은 많았지만 정확하게 + 자세하게 분석한 글은 찾지 못했다. 그래서 전체적인 프로세스를 다시 짚고 넘어가면서 어떻게 돌아가겠구나 직관적으로 이해할 수 있게, 각 특징들이 왜 이런 결과를 가져왔는지에 대해 보다 자세히 쓰고자 한다. (정리하다가 귀찮아서 또 생략할 수도 있지만 적어도 내가 논문을 읽다 막힌 부분이나 자세한 과정이 있으면 직관적으로 이해할 수 있는 부분들은 다 다루겠다) 대신 Yolo v1에 이미 설명한 내용들은 추가적으로 다루지 않을 것이니 Yolo v1 글을 먼저 읽고 오는 것을 추천한다. (시간이 된다면 Faster R-CNN도)
Abstract
SSD discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location(multiple feature map).
SSD의 알고리즘을 한 문장으로 정리하면 위와 같다. 아웃 풋을 만드는 공간을 나눈다(multi feature map). 각 피쳐맵(아웃풋맵)에서 다른 비율과 스케일로 default box를 생성하고 모델을 통해 계산된 좌표와 클래스값에 default box를 활용해 최종 bounding box를 생성한다.
1. Introduction
We introduce SSd, a single-shot detector for multiple categories that is faster than the previous state-of-the-art for single shot detectors(YOLO), and significantly more accurate, in fact as accurate as slower techniques that perform explicit region proposals and pooling(including Faster R-CNN).
한 마디로 성능, 속도면에서 내가 Top이다.
The core of SSD is predicting category scores and box offsets for a fixed set of default bounding boxes using small convolutional filters applied to feature maps.
어느 Detection Alogrithms 과 마찬가지로 box의 class 점수와, box의 위치좌표 크기를 에측하는데 고정된 기본 경계상자를 예측한다. 이 부분은 2.1 Model 부분과 2.2 Training 부분에서 더 자세히 다뤄볼 것이다.
To achieve high detection accuracy we produce predictions of different scales from feature maps of different scales, and explicitly separate predictions by aspect ratio.
정확도 향상을 위해 서로 다른 피쳐맵에서 서로 다른 스케일의 예측을 할 수 있게 했다. (Yolo v1은 최종 아웃풋은 한 피쳐맵이고, 각 그리드 셀당 2개의 바운딩 박스를 예측하는데 비해 SSD는 여러가지의 그리드셀(피쳐맵)을 가지고 각 피쳐맵당 여러가지의 (보통 6개)바운딩 박스를 가지기 때문) 이 역시 2.1 Model과, 2.2 Training에서 자세히 살펴볼 것.
Experiments include timing and accuracy analysis on models with varying input size evaluated on PASCAL VOC, COCO, and ILSVRC and are compared to a range of recent state-of-the-art approaches.
실험결과는 역시 걸린 시간과 정확도에 대한 분석을 포함하고, 파스칼, 코코, ILSVRC 데이터 셋으로 성능을 비교했고 제일 성능이 좋다.
2. The Single Shot Detector(SSD)
2.1 Model
Image Detection의 목적은 어떤 이미지 자료가 있으면 그 이미지 안에 들어있는 사물들을 찾아야(detect) 한다. 찾는다는 의미는 사물들의 위치와 사물이 이미지 안에 어디있는지 나타내야하며 따라서 우리는 그 사물이 어떤 사물인지에 대한 정보와 더불어 사물들의 위치정보 사물의 크기까지 예측해야하는 것이다. 따라서 Image Detection의 기본적인 Input은 이미지, Output은 이미지 안에 있는 사물들이 어떤 class 인지 나타내는 class 점수와, 그 사물의 offset(위치좌표 주로 중심 x,y좌표와 w,h, 너비와 높이)이 나와야한다. 이를 주의하고 아래의 SSD의 모델 구조를 살펴보자.

논문에 나와있는 모델의 구조는 위와 같은데 이해를 돕기 위해 전체적인 프로세스를 정리해보았다. 천천히 살펴보고 논문에 나와 있는 내용들을 살펴보자.

일단 SSD는 저해상도에서도 작동이 잘 돼서 300x300의 인풋이미지를 기본적으로 잡았다. 인풋 이미지를 기본적으로 처리할때는 VGG-16 모델을 가져와 conv4_3까지 적용하는 것을 base Network로 두고 처리하면 300x300x3 이 38x38x512로 바뀐다.

그런 다음 이 논문에서 강조하는 multi feature maps에 해당하는 부분인데, 38x38, 19x19, 10x10, 3x3, 1x1의 해당되는 피쳐맵은 output과 직결된 피쳐맵이다.

각 피쳐맵에서 적절한 conv 연산을 통해 우리가 예측하고자하는 bounding box의 class 점수와, offset을 얻게된다. 이때 conv filter size는 3 x 3 x (#바운딩박스 개수 x (class score + offset))이고 자세히 나와있진 않지만 stride=1, padding=1일 것으로 추정된다. 이 6개의 피쳐맵 각각에서 예측된 바운딩박스의 총 합은 8732개이다.
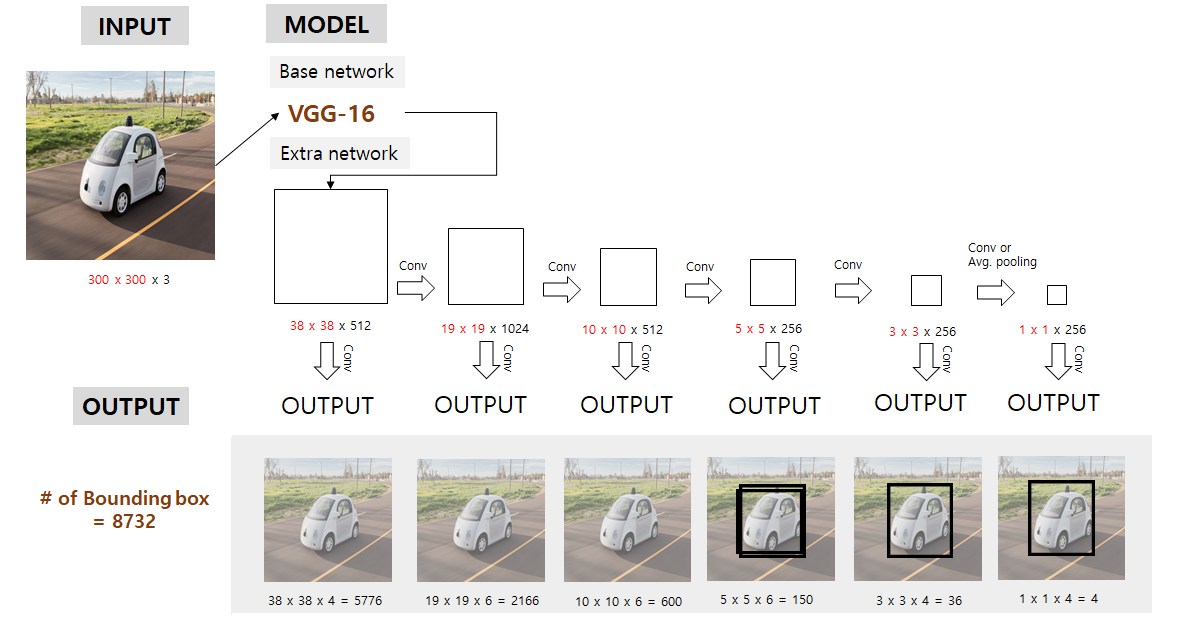
하지만 8732개의 바운딩박스의 아웃풋이 나온다고해서 그것을 다 고려하지 않는다.(이때의 고려는 마지막 Non-Max-Suppression 전 예측된 box들) 추후에 살펴보겠지만, 각 피쳐맵당 다른 스케일을 적용해 default 박스간의 IOU를 계산한다음 미리 0.5이상이 되는 box들만 1로 고려대상에 포함시키고 나머지는 0으로 만들어버려 위와 같이 3개의 피쳐맵에서만 box가 detect될 수 있다.

그리고 NMS 을 통해 최종 Detect된 결과는 오른쪽 위의 그림과 같다. 이제 아래의 소제목만 봐도 직관적으로 어떤 말을 하고 있는지 이해할 수 있을 것이다.
Multi-scale feature maps for detection
- 38x38, 19x19, 10x10, 5x5, 3x3, 1x1 의 피쳐맵들을 의미
- Yolo는 7x7 grid 하나뿐이지만 SSD는 전체 이미지를 38x38, 19x19, 10x10, 5x5, 3x3, 1x1의 그리드로 나누고 output과 연결
- 큰 피쳐맵에서는 작은 물체 탐지, 작은 피쳐맵에서는 큰 물체 탐지 (뒤의 2.2 training 부분에서 더 자세히 다룸)
Convolutional predictiors for detection
- 이미지부터 최종 피쳐맵까지는 Conv(3x3, s=2)로 연결
- Output과 연결된 피쳐맵은 3 x 3 x p 사이즈의 필터로 컨볼루션 연산. (Yolo v1은 Output과 Fully-Connected. 여기서 시간을 많이 단축시킴)
- 예측된 Output은 class, category 점수와, default box에 대응되는 offset을 구함
Default boxes and aspect ratios
We associate a set of default bounding boxes with each feature map cell, for multiple feature maps at the top of the network. The default boxes tile the feature map in a convolutional manner, so that the position of each box relative to its corresponding cell is fixed. At each feature map cell, we predict the offsets relative to the default box shapes in the cell,as well as the per-class scores that indicate the presence of a class instance in each of those boxes.
이 부분이 이해하기 어려웠는데, 내가 이해한 바로는 각 피쳐맵의 셀(5x5일경우 총 25개의 셀이 있음)에서 default bounding box라는 것을 만들고 그 default box와 대응되는 자리에서 예측되는 박스의 offset과 per-class scores(이때는 그 박스안에 물체가 있는지 없는지를 예측하는)를 예측한다. 이때 per-class scores를 클래스 확률로 생각하면 안되고 박스에 사물이 있는지 없는지 나타내는 값이라고 생각해야하며 이 부분에 대해서는 뒤에 Matching Strategy에 설명하겠다.
- 6개의 피쳐맵(마지막 6개의 피쳐맵, Output과 직결된)은 각각 Conv(3x3x(#bb x (c + offset))) 연산을 통해 Output 형성
- Output은 각 셀당 #bb개의 바운딩박스를 예측
2.2 Training
특히 training부분, loss fucntion(Objective)에 대한 부분을 자세히 설명한 블로그는 발견하지 못했다. 그만큼 한 두번봐서는 이해하기 힘들게 설명이 되어있다는 뜻이기도 하다. 왜냐하면 predicted box와 default box에 대한 정확한 구분이 필요하고 Fast R-CNN의 논문에서 anchor box와 loss function 부분의 이해가 필요하기 때문이기도 하다. 이 부분을 자세히 다룰 것이지만 그래도 이해가 되지 않는다면 Fast R-CNN이나, anchor box에 대한 자료를 한 번 읽어보고 다시 읽어보길 권한다. 역시 내용에 바로 들어가기에 앞서 정리된 도식으로 training 프로세스를 살펴보자.
이 모델에서 5x5 피쳐맵 부분만 따로 떼서 생각해보자.


Ground Truth Box. 우리가 예측해야하는 정답 박스.
Predicted Box. Extra Network의 5 x 5 의 feature map에서 output (predicted box)를 위해 conv 연산을 하면 총 5 x 5 x (6 x (21 + 4))의 값이 형성된다. ( = grid cell x grid cell x (# of bb x ( class + offset)))
Default Box. 하지만 5x5 feature map은 각 셀당 6개의 default box를 가지고 있다. 이때 default box의 w, h는 feature map의 scale에 따라 서로 다른 s 값과 서로 다른 aspect ratio인 a 값을 이용해 도출된다. 또 default box의 cx와 cy는 feature map size와 index에 따라 결정된다.
먼저 default box와 ground truth box 간의 IOU를 계산해 0.5 이상인 값들은 1(positive), 아닌 값들은 0으로 할당한다. (이는 아래서 x 에 해당하는 값) 예를 들어, 그림과 같이 5x5의 feature map의 13번째 셀(가운데)에서 총 6개의 default box와 predicted bounding box가 있는데, 같은 순서로 매칭되어 loss를 계산한다. 이는 아래의 loss function을 보면 더 쉽게 이해할 수 있을 것이다. 어쨌든, 매칭된(x=1, positive) default box와 같은 순서의 predicted bounding box에 대해서만 offset 에 대한 loss를 고려한다.

빨간색 점선이 matching 된 default box라고 한다면, 거기에 해당하는 cell의 같은 순서의 predicted bounding box의 offset만 update 되고 최종적으로는 아래와 같이 predict 된다.

Matching strategy
During training we need to determine which default boxes correspond to a ground truth detection and train the network accordingly. We begin by matching each ground truth box to the default box with the best jaccard overlap(= IOU). Unlike MultiBox, We then match default boxes to any ground truth with jaccard overlap higher than a threshold(0.5).
- ground truth 와 ‘default’ box를 미리 매칭 시킴
- 두 영역의 IOU가 0.5 이상인 것들을 match
Training objective


용어정리
- x^p_ij = {1,0} i번째 default box와 j번째 ground truth 박스의 category p에 물체 인식 지표. p라는 물체의 j번째 ground truth와 i번째 default box 간의 IOU 가 0.5 이상이면 1 아니면 0.
- N 은 # of matched default boxes
- l 은 predicted box (예측된 상자)
- g 는 ground truth box
- d 는 default box.
- cx, cy는 그 박스의 x, y좌표
- w, h는 그 박스의 width, heigth
- 알파는 1 (교차 검증으로부터 얻어진)
- loss fucntion 은 크게 2부분, 클래스 점수에 대한 loss와 바운딩 박스의 offset에 대한 loss로 나뉜다.

- 우리가 예측해야할 predicted box의 l^m_i(cx,cy,w,h)값들은 특이한 g햇 값들을 예측
- 이때 g햇의 cx,cy는 default box의 cx와 w,h로 normalize(?)된 것을 볼 수 있다.
- 이미 IOU가 0.5 이상만 된 것 부분에서 고려하므로, 상대적으로 크지 않은 값들을 예측해야하고 더불어 이미 0.5 이상 고려된 부분에서 출발하므로 비교적 빨리 수렴할 수 있을 것 같다.(이 부분은 주관적인 판단)
- 초기값은 default box에서 시작하지 않을까 싶음
- g햇의 w, h도 마찬가지
- 예측된 l 값들을 box를 표현할때(마지막 Test Output) 역시 default box의 offset 정보가 필요함.

- positive(매칭 된) class에 대해서는 softmax
- negative(매칭 되지 않은, 배경) class를예측하는 값으 c햇^0_i 값이고 별다른 언급은 없지만 background이면 1, 아니면 0의 값을 가져야함
- 최종적인 predicted class scores는 우리가 예측할 class + 배경 class 를 나타내는지표
Choosing scales ansd aspect ratios for default boxes
- default box를 위한 scale. 여래 크기의 default box 생성을 위해 다음과 같은 식 만듦.

- Smin = 0.2, Smax = 0.9
- 저 식에다 넣으면 각 feature map당 서로 다른 6개의 s 값들(scale 값들)이 나옴
- 여기에 aspect ratio = {1,2,3,1/2,1/3} 설정
- default box의 width는 s_k x 루트(a_r)
- a_r = 1 일경우 s’k = 루트(s_k x s(k+1))
- default box의 cx,cy는 k 번째 피쳐맵 크기를 나눠 사용
- 근데 굳이 이렇게 스케일을 저렇게 나눈 이유는 잘 모르겠음.. 대략 예측되는 상자가 정사각형이나, 가로로 조금 길쭉한 상자 세로로 조금 길쭉한 상자이니 2,3으로 임의로 정해도 잘 학습이 될테지만, 특이한 경우, 예를들어 가로 방향으로 걸어가는 지네같은 경우 저 비율로하면 0.5 threshold로 지정했을때 학습안됨. 학습할 이미지에 따라 aspect ratio를 조정해야할 필요가 있을텐데, 임의로 정한다면 비효율적. knn 같은 알고리즘을 활용하면 더 좋을 것 같음.
Hard negative Mining
- 대부분의 default box가 배경이므로 x_p_ij = 0인게 많음
- 따라서 마지막 class loss 부분에서 positive : negative 비율을 1:3으로 뽑음 (high confidence로 정렬해서)
Data augmentation
- 전체 이미지 사용
- 물체와 최소 IOU가 0.1, 0.3, 0.5, 0.7, 0.9가 되도록 패치샘플
- 랜덤 샘플링하여 패치 구함.
3. Experimental Results
PASCAL VOC, COCO Dataset에서 속도, 정확도 성능 SOTA. (TOP 1)
4. 끝으로
속도, 정확도 면에서 성능 SOTA가 된데는 다음과 같은 이유 덕분일 것이라 추측한다.
- Output layer와 FC 하지 않고 Conv를 이용. (Weight 수 급감, 속도 증가)
- 여러 feature 맵은, 한 이미지를 다양한 grid로 접근하고 다양한 크기의 물체들을 detect 할 수 있게함.
- default box 사용은 weight initialize와 normalize 효과를 동시에 가져올 수 있을듯
- 6개의 bounding box를 통해 겹치는 좌표의 다양한 물체 detect 가능.
분석하면서 생각이 든 한계점들이 몇 가지 안되지만 적어보자면 다음과 같다.
- 여러개의 feature map 의 detection을 다 계산하므로 computation cost +
- default box의 scale이나 aspect ratio는 비과학적. 비교적 쉽게 예측되는 ratio 외에 특이한 ratio를 가진 물체는 예측할 수 없음.
요약본은 내일 만들어야겠다.
참고자료

댓글