목표
이미지 처리를 위한 컨볼루셔널 신경망의 개념과 여러가지 컨볼루셔널 신경망의 구조 탐색
공부기간
2018.10.01.월 ~ 2018.10.02.화
참고자료
- CS231n 강의노트 Convolutional Neural Networks
- CS231n 강의노트 Convolutional Neural Netwokrs - 한글번역 (AI-Korea)
본문
컨볼루셔널 신경망(convolutional Neural Network 줄여서 CNN)에 대한 소개와 CNN을 이해하기 위해 어떤 개념들이 필요한지 살펴본다. 그런다음 CNN의 여러가지 변형 모델들을 살펴보고자 한다.
목차
- 아키텍쳐 개요
- CNN을 이루는 레이어들
- CNN 구조
1. 아키텍쳐 개요
일반 신경망은 이미지 데이터를 잘 다루지 못했다. CIFAR-10의 데이터의 경우 각 이미지가 32 X 32 X 3(가로, 세로, 3개 color 채널(Red, Green, Blue의 색상값들))로 이루어져 있고 첫번째 히든 레이어의 하나의 뉴런의 경우 32 X 32 X 3 = 3072개의 weight들이 필요하다. 만약 이미지 크기가 이것보다 훨씬 크다면? 그만큼 가중치가 더 많이 필요하고 이와 같은 fully connectivity는 심각한 낭비이며 많은 수의 모수는 overfitting으로 귀결된다.
CNN은 이와 달리 좀 더 합리적인 방향으로 아키텍쳐를 구성할 수 있다. CNN의 레이어들은 보통 가로, 세로, 깊이의 3개의 차원을 갖게된다.(깊이는 전체 신경망의 깊이가 아니라 이 레이어의 액티베이션 볼륨(activation volume)을 나타낸다) 예를 들어, CIFAR-10 이미지는 32x32x3(가로, 세로, 깊이)의 차원을 갖는 입력 액티베이션 볼륨(activation volume)이라고 볼 수 있다. 곧 자세히 구조를 살펴볼 것이지만 전체 이미지를 클래스 점수들로 이뤄진 하나의 벡터로 만들어주기 때문에 마지막 출력 레이어는 1x1x10(10은 CIFAR-10 데이터의 클래스 개수)의 차원을 갖게 된다. 이에 대한 그림은 아래와 같다.

조금 더 이해를 돕기 위해 위 그림을 좀 더 세부적으로 표현해보았다.

2. CNN을 이루는 레이어들
CNN (Convolutional Neural Networks)의 아키텍쳐에서는 크게 컨볼루셔널 레이어(Conv), 풀링 레이어(Pooling), Fully-connected 레이어라는 3개 종류의 레이어가 사용된다. 전체 CNN 아키텍쳐는 이 3 종류의 레이어들을 쌓아 만들어진다.

이런 레이어들과 activation function을 결합하여 위와 같은 CNN 모델을 만든다. 여기서 세부 설명을 다는 것보다 각 레이어가 무엇이고 어떤 역할을 하는지 살펴보고 다시 이 예제로 오도록 하자.
[1] Convolutional 레이어 (Conv 레이어)
컨볼류셔널(convolutional = conv) 레이어는 CNN의 가장 핵심 레이어이다. 이해를 돕기위해 CS231n 강의노트의 구성을 조금 바꾸었다. 먼저 Conv레이어가 어떻게 연산하는지 살펴보고, Conv 레이어에서 각 뉴런들의 지역적 연결성( local connectivity)와 그들의 공간상 배치(Spatial arrangement) 그리고 모수 공유(Parameter sharing)에 대해 알아보자.
Conv Layer 연산. Conv의 연산을 알기 위해서는 다음과 같은 개념들이 필요하다.
- 행렬 내적
- filter
- stride
- padding
하나씩 살펴보자.
행렬 내적. 같은 위치에 있는 값을 서로 곱한 것들의 합이다. 아래의 그림을 보자.

위의 A, B 두 행렬의 내적의 결과는 -1이다. 벡터나 행렬이나 그 보다 더 큰 차원인 tensor(3차원 이상)들의 내적은 마찬가지로 같은 위치에 있는 두 값을 곱한 것들의 합을 한 결과이다. 자세한 사항은 다음 링크를 참고하라.
Filter. 필터는 하나의 특징을 나타내는 weight라고 생각하면 편하다. 다음 그림을 보자.

5x5 input에서 빨간색 영역과 오른쪽 filter와의 내적의 결과는 3이다. 오른쪽 filter는 가운데 열에 모두 1이 있는 filter로 이 필터는 직선이 있는지 없는지 판단하는 좋은 weight들이라고 생각하면 된다. CNN에서의 필터는 보통 3차원으로 표현되며 하나의 특징을 나타내는 weight들이라고 생각하면 된다. CNN에서 filter와의 내적의 연산은 다음과 같은 모양으로 계산이 된다.

Stride. 스트라이드의 개념은 비교적 간단하다. filter가 한 번의 연산이 끝나고 얼만큼 이동할지를 나타내는 수치이다. 예를들어, 아래 그림은 한 번의 내적 연산후 1만큼 옆으로 이동한 경우이다.(Stride가 1일 때)

다음 그림은 stride가 2일 경우 연산 순서이다.

Padding(zero-padding). 가로 x 세로 양 옆에 0 값의 공간을 얼만큼 둘 것인지를 나타내는 지표로 5x5 image에 패딩이 1일 경우는 다음 그림과 같다.
이제 Conv 레이어를 이해하는 데 필요한 모든 개념들을 다 살펴보았다. 다음으로 이 구조의 지역적 연결성, 공간적 배치, 모수 공유를 살펴보자.
지역적 연결성(local connectivity) 이미지의 데이터의 경우 기존 신경망에서 사용한 fully connectivity는 실용적이지 않다. 대신 레이어의 각 뉴런을 입력 볼륨의 로컬한 영역에 연결할 것이다. 이 영역을 리셉티브 필드(receptive field = filter)라고 불리고 이는 하이퍼파라미터이다. 가로 세로 중 일부 로컬한 영역을 보지만 깊이는 전체를 다 본다( 총 깊이를 모두 다 다룬다는 뜻으로 공간적 차원은 가로 x 세로라고 보면 된다. 깊이는 몇이 되었든 다 다룰 것이므로 공간적 차원에서 제외한다)
예제 1. 예를 들어 입력 볼륨의 크기가 [32 x 32 x 3] (가로 x 세로 x 채널의값(RGB))라고 하자. 만약 리셉티브 필드의 크기(filter)가 5x5라면 Conv 레이어의 각 뉴런은 입력볼륨 [5 x 5 x 3] 크기의 영역에 각 가중치를 가지게 된다(5x5x3 = 75개의 가중치).
예제 2. 입력 볼륨의 크기가 [16 x 16 x 20] 이라고 하자. 3 x 3 크기의 리셉티브 필드(filter)를 사용하면 각 뉴런은 입력볼륨 [3 x 3 x 20]의 크기의 filter의 각 weight와의 연결(3x3x20=180)을 가지게 된다.
예제 3. 입력 볼륨의 크기가 [n x n x 3] 이라고 하자. 3 x 3 크기의 리셉티브 필드(filter)를 사용하면 한 개의 뉴런은 입력볼륨 [3 x 3 x 3]의 크기의 filter에 각 weight와의 연결(내적 할 때 입력 볼륨의 부분과 filter의 weight와의 곱으로 이루어진, 3 x 3 x 3 = 27)을 가지게 된다. 아래 그림 참고.

공간적 배치(Spatial arrangement). 출력 볼륨은 4개의 하이퍼파라미터로부터 결정된다. 이 때 4개의 하이퍼파라미터는 앞에서 살펴본 filter의 사이즈(F),stride(S), zero-padding(P), filter의 개수(K)이다. 다음 예제를 보자.

- 공간적 배치에 관한 그림. 이 예제에서는 가로/세로 공간적 차원 중 하나만 고려한다 (x축). 리셉티브 필드의 사이즈 F=3, 입력 사이즈 W=5, 제로 패딩 P=1.
- 이 예에서 뉴런들의 가중치(filter가 가지는 값)은 [1,0,-1] (가장 오른쪽) 이며 bias는 0이다. 이 가중치는 노란 뉴런들 모두에게 공유된다 (아래에서 parameter sharing에 대해 살펴보라).
- 좌: 뉴런들이 stride S=1을 갖고 배치된 경우, 출력 사이즈는 (5-3+2)/1 +1 = 5이다.
- 우: stride S=2인 경우 (5-3+2)/2 + 1 = 3의 출력 사이즈를 가진다.
- Stride S=3은 사용할 수 없다. (5-3+2) = 4가 3으로 나눠지지 않기 때문에 출력 볼륨의 뉴런들이 깔끔히 배치되지 않는다.
실제 예제. 이미지넷 대회에서 우승한 Krizhevsky et al. 의 모델의 경우 [227x227x3] 크기의 이미지를 입력으로 받는다. 첫 번째 컨볼루션 레이어에서는 리셉티브 필드 F=11 , stride S=4를 사용했고 제로 패딩은 사용하지 않았다 P=0. (227 - 11)/4 +1=55 이고 컨볼루션 레이어의 깊이는 K=96 이므로 이 컨볼루션 레이어의 크기는 [55x55x96]이 된다. 각각의 555596개 뉴런들은 입력 볼륨의 [11x11x3]개 뉴런들과 연결되어 있다. 그리고 각 깊이의 모든 96개 뉴런[55x55]들은 입력 볼륨의 같은 [11x11x3] 영역에 서로 다른 가중치를 가지고 연결된다.
모수 공유(parameter sharing) 위의 Krizhevsky et al. 의 모델의 경우 첫 번째 컨볼루션 레이어에는 55 x 55 x 96 = 290,400 개의 뉴런이 있고 각 뉴런은 11 x 11 x 3 = 363 개의 가중치(weight)와 1개의 바이어스를 가진다. 만약 각 뉴런에 붙는 가중치들이 모두 다 다르다면 총 290,400 x 363 = 105,705,600개의 파라미터를 가지게 되는데 이 수는 너무 크다!

사실 다음과 같은 가정을 통해서 파라미터를 크게 줄이는 것이 가능하다. (x, y) 어떤 위치에서 어떤 filter(= 그 필터가 가지는 특징)이 유용하게 사용되었다면, 이 filter는 다른 위치 (x2, y2)에서도 유용하게 사용될 수 있다. 3차원 볼륨의 한 슬라이스(깊이 차원으로 자른 2차원 슬라이스)를 depth slice라고 하자. 위의 예에서 [55x55x96]사이즈의 볼륨의 한 depth의 slice는 [55x55]이다. 이제부터는 한 depth slice에는 공통된, 같은 가중치와 바이어스를 가지도록 제한한다. 따라서 위의 예제에서의 필요한 파라미터수는 (depth slice 사이즈) x depth(깊이)가 되므로 (11113) x (96) = 34,848 개의 서로 다른 가중치(weight)를 가지게 된다. 여기에 각 depth당 bias 1개씩을 더하면 96개의 서로 다른 bias가 있고 이 둘의 합은 총 파라미터수인 34,848+96 = 34,944개가 된다. 실제 backpropagation 과정에서 각 depth slice 내의 모든 뉴런들이 가중치에 대한 gradient를 계산하겠지만, 가중치 업데이트를 할 때에는 이 gradient들을 합해 사용한다.
컨볼루션 레이어의 가중치는 filter 또는 kernel이라고 부른다. 왼쪽 입력볼륨과 filter 하나의 내적의 결과를 액티베이션 맵이라고 하고, 위의 예에서는 [227x227x3]의 입력볼륨에 [11x11x3]의 필터를 S = 4, P = 0 이므로 액티베이션 맵 사이즈는 [55 x 55] (227-11)/4+1 = 55)가 되며 K 가 96이므로 이 액티베이션 맵이 96개가 있는 [55 x 55 x 96]의 출력 볼륨이 나온다.
가끔은 파라미터 sharing에 대한 가정이 부적절할 수도 있다. 특히 입력 이미지가 중심을 기준으로 찍힌 경우 (예를 들면 이미지 중앙에 얼굴이 있는 이미지), 이미지의 각 영역에 대해 완전히 다른 feature들이 학습되어야 할 수 있다. 눈과 관련된 feature나 머리카락과 관련된 feature 등은 서로 다른 영역에서 학습될 것이다. 이런 경우에는 파라미터 sharing 기법을 접어두고 대신 Locally-Connected Layer라는 레이어를 사용하는 것이 좋다
Numpy 에제. 코드를 통해 살펴보자. 입력볼륨을 numpy 배열 X라고 하면, X[가로,세로,깊이]로 각 위치 좌표의 값을 나타낼 수 있다. i 번째 depth의 액티베이션 맵은 X[ : , : , i]로 나타낼 수 있다. 만약 X.shpae : (11,11,4)이고 제로 패딩을 사용하지 않으며 ( P = 0 ), 필터 크기는 5(F = 5), stride는 2(S = 2)라고 하자. filter의 사이즈는 [5 x 5 x 4]이고 출력 볼륨의 spatial 크기는(가로 또는 세로의 길이) (11-5)/2 +1 = 4 가 된다. 따라서 출력 볼륨의 사이즈는 [4,4, K] 이다.
아래는 출력볼륨이 V이고, 입력 볼륨 X의 [: ,:5,:] (=0~4까지 세로는 고정돼 있고 가로만 stride)와 첫 번째 Filter(weight, 아래에서는 W0)간의 내적의 결과는 [4,1,1]이고 4번의 내적 결과는 아래와 같다. 이때 두 3차원의 * 는 내적 연산이다. (같은 위치의 값들을 곱한 것들의 합)
V[0,0,0] = np.sum(X[:5,:5,:] * W0) + b0 # np.dot(X[:5,:5,:],W0) + b0
V[1,0,0] = np.sum(X[2:7,:5,:] * W0) + b0
V[2,0,0] = np.sum(X[4:9,:5,:] * W0) + b0
V[3,0,0] = np.sum(X[6:11,:5,:]* W0) + b0
첫 번째 0~4까지의 세로에 대한 연산이 끝났으므로 다음 줄에 대한 연산을 끝까지 해주면
# X[:,2:7,:]와 연산 결과
V[0,1,0] = np.sum(X[:5,2:7,:] * W0) + b0
V[1,1,0] = np.sum(X[2:7,2:7,:] * W0) + b0
V[2,1,0] = np.sum(X[4:9,2:7,:] * W0) + b0
V[3,1,0] = np.sum(X[6:11,2:7,:]* W0) + b0
# X[:,4:9,:]와 연산 결과
V[0,2,0] = np.sum(X[:5,4:9,:] * W0) + b0
V[1,2,0] = np.sum(X[2:7,4:9,:] * W0) + b0
V[2,2,0] = np.sum(X[4:9,4:9,:] * W0) + b0
V[3,2,0] = np.sum(X[6:11,4:9,:]* W0) + b0
# X[:,6:11,:]와 연산 결과
V[0,3,0] = np.sum(X[:5,6:11,:] * W0) + b0
V[1,3,0] = np.sum(X[2:7,6:11,:] * W0) + b0
V[2,3,0] = np.sum(X[4:9,6:11,:] * W0) + b0
V[3,3,0] = np.sum(X[6:11,6:11,:]* W0) + b0
따라서 입력 볼륨 X와 첫 번째 필터 W0의 출력 볼륨V의 사이즈는 [4x4x1]이 된다. 그렇다면 K가 2라면? 서로 다른 커널, 필터의 수가 2개이므로 출력 볼륨 V의 사이즈는 [4x4x2]의 사이즈를 가지게 된다.
# X 와 W1 (2번째 필터)와의 연산
# X[:,:5,:]와 연산 결과
V[0,0,1] = np.sum(X[:5,:5,:] * W1) + b1 # np.dot(X[:5,:5,:],W1) + b1
V[1,0,1] = np.sum(X[2:7,:5,:] * W1) + b1
V[2,0,1] = np.sum(X[4:9,:5,:] * W1) + b1
V[3,0,1] = np.sum(X[6:11,:5,:]* W1) + b1
# X[:,2:7,:]와 연산 결과
V[0,1,1] = np.sum(X[:5,2:7,:] * W1) + b1
V[1,1,1] = np.sum(X[2:7,2:7,:] * W1) + b1
V[2,1,1] = np.sum(X[4:9,2:7,:] * W1) + b1
V[3,1,1] = np.sum(X[6:11,2:7,:]* W1) + b1
# X[:,4:9,:]와 연산 결과
V[0,2,1] = np.sum(X[:5,4:9,:] * W1) + b1
V[1,2,1] = np.sum(X[2:7,4:9,:] * W1) + b1
V[2,2,1] = np.sum(X[4:9,4:9,:] * W1) + b1
V[3,2,1] = np.sum(X[6:11,4:9,:]* W1) + b1
# X[:,6:11,:]와 연산 결과
V[0,3,1] = np.sum(X[:5,6:11,:] * W1) + b1
V[1,3,1] = np.sum(X[2:7,6:11,:] * W1) + b1
V[2,3,1] = np.sum(X[4:9,6:11,:] * W1) + b1
V[3,3,1] = np.sum(X[6:11,6:11,:]* W1) + b1
요약.
- 입력을 받는다 [가로x세로x깊이] ( = W1, H1, D1)
- 4개의 하이퍼파라미터를 정한다.
- K : 필터 개수
- F : 필터의 가로 or 세로 spatial 크기
- S : 스트라이드
- P : 제로패딩
- 출력 볼륨은 [W2, H2, D2]이다.
- W2 = (W1-F+2P)/S + 1
- H2 = (H1-F+2P)/S + 1
- D2 = K
- 이 때 파라미터의 총 개수는 F x F x K (weight) + K(K depth당 하나의 bias)이다.
컨볼루션 데모. 아래는 컨볼루션 레이어 데모이다. 3차원 볼륨은 시각화하기 힘드므로 각 행마다 depth slice를 하나씩 배치했다. 각 볼륨은 입력 볼륨(파란색), 가중치 볼륨(빨간색), 출력 볼륨(녹색)으로 이뤄진다. 입력 볼륨의 크기는 W1=5,H1=5,D1=3이고 컨볼루션 레이어의 파라미터들은 K=2,F=3,S=2,P=1이다. 즉, 2개의 3×3크기의 필터가 각각 stride 2마다 적용된다. 그러므로 출력 볼륨의 spatial 크기 (가로/세로)는 (5 - 3 + 2)/2 + 1 = 3이다. 제로 패딩 P=1 이 적용되어 입력 볼륨의 가장자리가 모두 0으로 되어있다는 것을 확인할 수 있다. 아래의 영상에서 하이라이트 표시된 입력(파란색)과 필터(빨간색)이 elementwise로 곱해진 뒤 하나로 더해지고 bias가 더해지는걸 볼 수 있다.
- 입력 [ 5 x 5 x 3 ] ( = (W1, H1, D1))
- 4개의 하이퍼파라미터
- K = 2
- F = 3
- S = 2
- P = 1
- 출력 [ 3 x 3 x 2 ] ( = (W2, H2, D2))
- W2 = ( 5 - 3 + 2*1) / 2 + 1 = 3
- H2 = ( 5 - 3 + 2*1) / 2 + 1 = 3
- D2 = K = 2
Backpropagation. 입력 볼륨과 필터의 내적으로 이루어져 있으므로 쉽게 역전파 과정을 이해할 수 있다.
[2] 풀링 레이어
컨볼류션 레이어(Conv Layer)의 중간중간 마다 풀링레이어를 넣는 것이 일반적이다. 이 레이어가 하는 일은 파라미터의 개수, 연산량을 줄이는 것이다. 맥스 풀링이 가장 일반적이다.
- 입력 W1 x H1 x D1
- 2가지의 하이퍼파라미터를 정한다.
- F : 풀링 필터의 (가로 or 세로 크기)
- S : 스트라이드
- 출력 W2 x H2 x D2 (풀링 레이어)
- W2, H2 = (W1,H2 - F)/2 + 1
- D2 = D1
- 풀링 필터는 weight가 존재하지 않음. 그래서 풀링하는 영역을 필터라고 하지 않고 그냥 풀링이라고 한다.
실전에서는 max풀링이 널리 쓰이며, F=2, S=2로 설정한다. 또 하나의 설정 방법은 F=3, S=2의 풀링(overlapping pooling)이다.
Backpropagation. Backpropagation 챕터에서 max(x,y)의 backward pass는 그냥 forward pass에서 가장 큰 값을 가졌던 입력의 gradient를 보내는 것과 같다고 배운 것을 기억하자. 그러므로 forward pass 과정에서 보통 max 액티베이션의 위치를 저장해두었다가 backpropagation 때 사용한다.
최근 발전된 내용들. 풀링 레이어가 보통 representation의 크기를 심하게 줄이기 때문에 (이런 효과는 작은 데이터셋에서만 오버피팅 방지 효과 등으로 인해 도움이 됨), 최근 추세는 점점 풀링 레이어를 사용하지 않는 쪽으로 발전하고 있다고 한다.
- Fractional Max-Pooling 2x2보다 더 작은 필터들로 풀링하는 방식. 1x1, 1x2, 2x1, 2x2 크기의 필터들을 임의로 조합해 풀링한다. 매 forward pass마다 grid들이 랜덤하게 생성되고, 테스트 때에는 여러 grid들의 예측 점수들의 평균치를 사용하게 된다.
- Striving for Simplicity: The All Convolutional Net 라는 논문은 컨볼루션 레이어만 반복하며 풀링 레이어를 사용하지 않는 방식을 제안한다. Representation의 크기를 줄이기 위해 가끔씩 큰 stride를 가진 컨볼루션 레이어를 사용한다.
[3] Normalization 레이어
효과가 없어 최근에 별로 사용하지 않는다고 한다.
[4] Fully-Connected 레이어
앞의 신경망 챕터에서 다뤘던 내용으로 인풋 뉴런과 아웃풋 뉴런이 모두 연결된 층을 말한다.
[5] FC 레이어를 Conv 레이어로 변환
FC -> Conv 변환. 실전에서 매우 유용하다. 224 x 224 x 3의 이미지를 입력으로 받고, Conv레이어와 Pooling 레이어를 이용해 7 x 7 x 512 의 출력 볼륨을 만드는 컨볼루셔널 아키텍쳐를 생각해보자.
( 사실 위는 AlexNet의 구조인데 계산을 해보니까 저런 출력을 만들 수 없었다. 대신 image가 224 x 224 x 3이 아닌 227 x 227 x 3이라고 생각해야 한다. 원 구조는 다음링크를 참고하길 바란다)
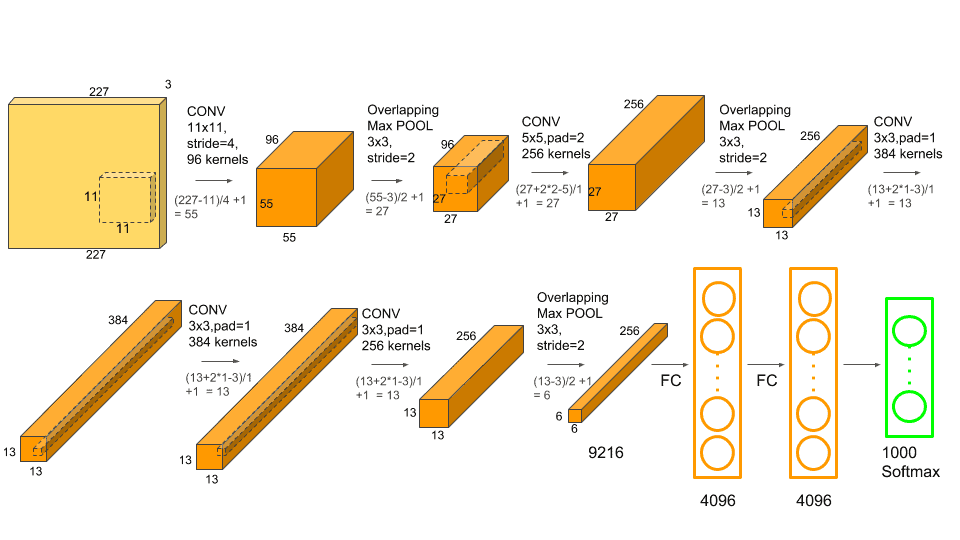{kind=link}
- [7x7x512]의 입력 볼륨(위의 컨볼루셔널 아키텍쳐에서 최종 출력 볼륨)을 받는 첫번째 FC 레이어를 F=7의 필터 크기를 갖는 Conv 레이어로 바꾼다. 이때 출력 볼륨의 크기는 [1x1x4096]이 된다. 이때 사용된 필터의 하이퍼파라미터는 F=7, S=1, P=0, K =4096이 된다.
- 두 번째 FC 레이어를 F=1 필터 사이즈의 Conv 레이어로 바꾼다. 이 때 출력 볼륨의 크기는 [1x1x4096]이 된다.
- 같은 방식으로 마지막 FC레이어는 F=1의 Conv 레이어를 바꾼다. 출력 볼륨의 크기는 [1x1x1000]이 된다. 이때 사용한 필터의 하이퍼파라미터는 F=1, S=1, P=0, K=1000이다.
다시 말해, 필터의 크기를 입력 볼륨의 크기와 같게 만들면 우리가 원하는 한 결과값에 모든 입력 뉴런과 필터의 웨이트들이 곱해져 fully connect와 동일한 연산과정을 가지게 된다.
만약 이미지의 크기가 달라지면 어떻게 될까? 예를 들어,224x224 크기의 이미지를 입력으로 받으면 [7x7x512]의 볼륨을 출력하는 이 아키텍쳐에, ( 224/7 = 32배 줄어듦 ) 된 아키텍쳐에 384x384 크기의 이미지를 넣으면 [12x12x512] 크기의 볼륨을 출력하게 된다 (384/32 = 12 이므로). 이후 FC에서 CONV로 변환한 3개의 CONV 레이어를 거치면 [6x6x1000] 크기의 최종 볼륨을 얻게 된다 ( (12 - 7)/1 +1 =6 이므로). [1x1x1000]크기를 지닌 하나의 클래스 점수 벡터 대신 384x384 이미지로부터 6x6개의 클래스 점수 배열을 구했다는 것이 중요하다. 이 점수 배열들에 평균을 취해서(average pooling 같은) 하나의 값을 구할 수 있다.
이 부분이 잘 이해가 가지 않는다면 다음 링크를 참고하면 좋을 것이다.
3. CNN 구조 (ConvNet Architectures)
컨볼루셔널 네트워크의 구조는 Conv 레이어, Pool 레이어, FC 레이어 그리고 actiavation fucntion의 조합으로 이루어져 있다.
[1] Layer Pattern
보통 구조는 다음과 같다.
INPUT -> [ [ CONV -> RELU ] x N -> POOL? ] x M -> [ FC -> RELU] x K -> FC
- N개의 Conv 레이어와 actiavtion function의 조합 다음 Pooling (? = 선택사항)
- 위의 구조를 M개 쌓은다음 FC 레이어 + activation의 K개 조합
- 마지막 출력볼륨을 위해 FC
- 보통 0 <=
N< 3 ,M>= 0, 0 <=K< 3
작은 사이즈의 필터로 많이. 큰 리셉티브 필드를 가지는 Conv 레이어보다 여러개의 작은 사이즈의 필터를 가진 Conv 레이어를 쌓는 것이 좋다. 쌓을 때 사이에는 activation function이 들어간다. 3x3 크기의 CONV 레이어 3개를 쌓는다고 생각해보자 (물론 각 레이어 사이에는 비선형 함수를 넣어준다). 이 경우 첫 번째 CONV 레이어의 각 뉴런은 입력 볼륨의 3x3 영역을 보게 된다. 두 번째 CONV 레이어의 각 뉴런은 첫 번째 CONV 레이어의 3x3 영역을 보게 되어 결론적으로 입력 볼륨의 5x5 영역을 보게 되는 효과가 있다. 비슷하게, 세 번째 CONV 레이어의 각 뉴런은 두 번째 CONV 레이어의 3x3 영역을 보게 되어 입력 볼륨의 7x7 영역을 보는 것과 같아진다. 하지만 단순히 7x7 filter만 쓰게되면 몇 가지의 단점이 생긴다. 3x3 3개의 conv 레이어는 중간에 비선형함수(activation function)을 넣게되어 좋은 feature를 만들 수 있는 반면, 7x7 짜리 필터를 가지는 conv 레이어는 단순히 선형 결합이다. 따라서 전자가 더 좋은 특징들을 만들 수 있다. 또 파라미터 개수를 비교해보면 (모두 K개의 커널(혹은 depth)를 가진다고 할때), 전자는 3개의 레이어 x (K x (3 x 3 x K)) = 27K^2, 후자는 1개의 레이어 x (K x (7 x 7 x K)) = 49K^2이다. 하지만 Backpropagation을 할 때는 중간의 결과물들을 저장해야할 결과물들이 전자에 비해 적기에 메모리를 적게 사용한다는 장점은 있다.
[2] Layer Sizing Pattern
ConvNet의 각 레이어에서 주로 사용되는 하이퍼파라미터 세팅을 정리해보자.
Conv 레이어. (4개)
- K = K (자유)
- F = 3 (최대 5)
- P = 1 (P = (F-1)/2 )
- S = 1
Pool 레이어. (2개)
- F = 2
- S = 2
크기 축소. 보통 Conv 레이어에서는 F = 3, P = 1, S = 1으로 인풋볼륨이 [ W1 x H1 x D1 ]라고하면 위의 필터로 거친 결과는 W2 = (W1- 3 + 2)/1 + 1 = W1, H2 = H1 이므로 D1 와 K 가 똑같다는 전제아래 크기가 축소되지는 않는다. 따라서 Pool 레이어만 다운샘플링을 책임지게 된다.
왜 Conv 레이어에서 Stride가 1? 실전에서 성능이 제일 좋아서. 아마 모든 부분을 꼼꼼히 보고 가니까 각 부분에 대한 특징들을 잘 잡을 수 있어서일 것.
왜 제로 패딩을 사용하는가? 제로패딩을 이용하면 사이즈를 계속 유지시킬 수 있고, 이게 성능이 잘 나온다고 한다. 또 경계부분도 빠지지 않고 다 볼 수 있게 해준다.
메모리 제한에 대한 타협. 어떤 경우에는 (특히 예전에 나온 ConvNet 구조에서), 위에서 다룬 기법들을 사용할 경우 메모리 사용량이 매우 빠른 속도로 늘게 된다. 예를 들어 224x224x3의 이미지를 64개의 필터와 stride 1을 사용하는 3x3 CONV 레이어 3개로 필터링하면 [224x224x64]의 크기를 가진 액티베이션 볼륨을 총 3개 만들게 된다. 이 숫자는 거의 1,000만 개의 액티베이션 값이고, (이미지 1장 당)72MB 정도의 메모리를 사용하게 된다 (액티베이션과 그라디언트 각각에). GPU를 사용하면 보통 메모리에서 병목 현상이 생기므로, 이 부분에서는 어느 정도 현실과 타협을 할 필요가 있다. 실전에서는 보통 첫 번째 CONV 레이어에서 타협점을 찾는다. 예를 들면 첫 번째 CONV 레이어에서 7x7 필터와 stride 2 (ZF net)을 사용하는 케이스가 있다. AlexNet의 경우 11x11 필터와 stride 4를 사용한다.
[3] Case study
LeNet, AlexNet, ZF Net, GoogleNet, VGGNet, ResNet 등이 있는데 이에 대한 설명은 다음 링크를 참고하라.
다음은 VGGNet에 대한 각 레이어들의 크기와 파라미터 수이다. Conv 레이어에서는 F=3, S=1, P=1이고 Pool 레이어에서는 F=2, S=2, P=0이다.
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
[4] Computation Considerations
이 부분은 AI-Korea에 번역된 설명이 좋아서 그대로 가져왔다.
ConvNet을 만들 때 일어나는 가장 큰 병목 현상은 메모리 병목이다. 최신 GPU들은 3/4/6GB의 메모리를 내장하고 있다. 가장 좋은 GPU들의 경우 12GB를 갖고 있다. 메모리와 관련해 주의깊게 살펴 볼 것은 크게 3가지이다.
- 중간 단계의 볼륨 크기: 매 레이어에서 발생하는 액티베이션들과 그에 상응하는 그라디언트 (액티베이션과 같은 크기)의 개수이다. 보통 대부분의 액티베이션들은 ConvNet의 앞쪽 레이어들에서 발생된다 (예: 첫 번째 CONV 레이어). 이 값들은 backpropagation에 필요하기 때문에 계속 메모리에 두고 있어야 한다. 학습이 아닌 테스트에만 ConvNet을 사용할 때는 현재 처리 중인 레이어의 액티베이션 값을 제외한 앞쪽 액티베이션들은 버리는 방식으로 구현할 수 있다.
- 파라미터 크기: 신경망이 갖고 있는 파라미터의 개수이며, backpropagation을 위한 각 파라미터의 그라디언트, 그리고 최적화에 momentum, Adagrad, RMSProp 등을 사용한다면 이와 관련된 파라미터들도 캐싱해 놓아야 한다. 그러므로 파라미터 저장 공간은 기본적으로 (파라미터 개수의)3배 정도 더 필요하다.
- 모든 ConvNet 구현체는 이미지 데이터 배치 등을 위한 기타 용도의 메모리를 유지해야 한다.
일단 액티베이션, 그라디언트, 기타용도에 필요한 값들의 개수를 예상했다면, GB 스케일로 바꿔야 한다. 예측한 개수에 4를 곱해 바이트 수를 구하고 (floating point가 4바이트, double precision의 경우 8바이트 이므로), 1024로 여러 번 나눠 KB, MB, GB로 바꾼다. 만약 신경망의 크기가 너무 크다면, 배치 크기를 줄이는 등의 휴리스틱을 이용해 (대부분의 메모리가 액티베이션에 사용되므로) 가용 메모리에 맞게 만들어야 한다.
마무리
중간에 조금 잘못된 부분도 있고 설명이 더 있으면 좋을만한 부분이 많아서 자료를 찾고 없으면 만드느라 생각보다 오래 걸렸다.
- CNN에 대해 깊이 이해함
- Image Detection에 관한 논문부터 Review
- CS231n 남은 2개의 강의노트 정리

댓글